自16年购入该机器基础配置,换了cpu及内存,换了400W电源,买过两块阵列卡( HP P410 , LSI 9217-8i IT模式 ),两块显卡( R7 250 E4 2G , GTX 1650 4G ),及7块硬盘(5块4T红盘,2块10T西数桌面盘),前前后后 ,折腾了无数次 ,现将我的经历分享给大家,我本身需求其实很简单。
1.需要一个存储服务器,由于使用频率不高,所以希望硬盘尽量休眠减少损耗,目前群辉(DSM)功能比较多,操作也比较方便。
2.需要一个HTPC用于连接电视播放视频。
3.偶尔可能需要一个虚拟机用于安装CentOS、Openwrt、Ubuntu之类的进行测试 。
刚开始的方案一 :
Gen8(4块4T红盘+1块512G SSD)在SSD中 安装Windows Server 2012 R2,并通过USB引导到第五块硬盘(gen8 不改线SSD接的是sata5)启动Windows,使用Hyper-V虚拟机虚拟DSM,然后把除了系统盘外的其他硬盘都直通给DSM。
缺点:直通给DSM的硬盘无法休眠,正常低功耗运行的时候功耗在60W左右(4块4T红盘+一块 R7 250 E4 2G 显卡),而且群辉版本最高到5.2。
试过硬盘由Windows控制,然后通过NFS共享给DSM,休眠 的问题是解决了,但是群辉的部分套件功能异常。于是想着换ESXI,通过直通 SATA控制器的方式给DSM,于是有了下面的方案。
方案二:ESXI(版本6.0,6.5的有BUG)直通SATA控制器给DSM,显卡直通给HTPC。
方案二第一阶段
ESXI安装在32G的TF卡中,SATA控制器直通给DSM,后其他系统就没有地方安装了,如果使用DSM通过NFS共享的空间安装,也会影响到DSM的休眠,所以想着看看能不能直接把USB 3.0用起来,让SSD通过USB3.0 连接到ESXI。最后参考 https://www.virten.net/2015/10/usb-devices-as-vmfs-datastore-in-vsphere-esxi-6-0/ 增加了一个SSD 的USB3.0存储。
通过SSH连接ESXI;暂停 ESXI的一个USB相关的服务,这个服务暂停后将无法在ESXI中直接添加USB设备给虚拟机,只能直通USB控制器。
/etc/init.d/usbarbitrator stop停止这个服务的自动启动
chkconfig usbarbitrator off列出所有硬盘,在其中找到你的盘(通常6.0是mpx.vmhba开头,6.5是naa开头),我的盘是mpx.vmhba32:C0:T0:L0
ls /dev/disks/把你的硬盘修改成GPT分区模式
partedUtil mklabel /dev/disks/mpx.vmhba32:C0:T0:L0 gpt创建硬盘分区需要知道开始位置 和结束位置,一般开始位置都是2048,我们就只要得到结束位置即可
partedUtil getptbl mpx.vmhba32:C0:T0:L0返回:
gpt
1947 255 63 31293440 通过返回的值计算结束位置
eval expr $(partedUtil getptbl /dev/disks/mpx.vmhba32:C0:T0:L0 | tail -1 | awk '{print $1 " \* " $2 " \* " $3}') - 1创建VMFS分区
partedUtil setptbl /dev/disks/mpx.vmhba32:C0:T0:L0 gpt "1 2048 31278554 AA31E02A400F11DB9590000C2911D1B8 0"挂载VMFS分区
vmkfstools -C vmfs5 -S upan(usb显示名称) /dev/disks/mpx.vmhba32:C0:T0:L0:1因为停掉了ESXI的一个USB服务,导致不能直接把USB设备添加到虚拟机,所以直通了USB2.0的#2驱动器给HTPC,千万不能直通#1,会导致tf卡也被直通进来导致Esxi无法写tf卡,任何配置信息的修改都将失败。
这样操作以后HTPC不休眠,只设置一定时间关闭显示器,就可以通过外接的鼠标键盘直接激活。DSM也获得了SATA的控制权,硬盘也可以休眠了,低功耗运行的时候功耗40W左右( 4块4T红盘+一块 R7 250 E4 2G 显卡+512G SSD )。
方案二第二阶段
虽然DSM可以休眠了,但是还是经常被无故唤醒,查各种日志,看是哪些服务做了什么,大部分都是系统做的,有人访问,会唤醒写日志,定时服务会唤醒,等等,于是就想看看能不能把系统独立出来,于是有了阶段二。
我增加了一块虚拟的100G的硬盘给DSM,然后把所有应用以及一些常用的数据放在这个盘里,其他的盘则进行电机休眠。具体设置休眠的方法参考我之前写的一篇文章
后来需要测试下一个程序的性能,买了块HP P410阵列卡及一个5盘位的硬盘笼子,挂了4块换下来的快要坏掉的SAS 300G(Dell 服务器上会提示异常,估计是坏道很多了,快要坏了)硬盘组raid0。这样担心原来200W电源不够,于是有换了400W的二手台达电源。这个时候硬盘笼子里多了个空位,于是又补了块4T的盘进去;后面测试完后,就把阵列卡移走了及sas盘移走了。
再后来玩了一段时间pt,原先的5块硬盘组的raid6空间不够用,于是又买了两块10T的硬盘加一块 LSI 9217-8i IT模式 阵列卡;之前买的HP P410 发热很大,硬盘没办法休眠,支持SAS盘; LSI 9217-8i IT模式 ,以为可以支持休眠,但经测试还是没办法休眠,不过群辉可以读到硬盘SMART信息。后来不玩PT,移除了阵列卡及两块硬盘,回到了基本的5块4T硬盘组 Raid6,准备等4T盘坏了后慢慢换成10T盘 ,也不打算再外挂第5块盘了,影响美观。
目前这样配置已经基本可以使用,硬盘也可以休眠了(这个休眠只是电机),休眠的时候功耗在50W不到(5块4T红盘组的Raid6+ R7 250 E4 2G 显卡+intel 512G SSD );近期因为需要输出4k 60HZ,换了 GTX 1650 4G显卡,也可以轻松直通给Windows使用,这张卡不需要设置就可以直通,只是直通后无法使用,需要在虚拟机 .vmx 配置文件中增加以下内容。
hypervisor.cpuid.v0 = “FALSE”
方案三 :
由于ESXI6.0需要占用4G左右的内存,分给DSM 1GB,剩余只有10GB给到HTPC,由于两个系统都直通了硬件,分配内存只能全部预留,跑XPlane 还是比较勉强,所以想着ESXI换成PVE,能再多2-3G的内存给到HTPC,于是有了方案三。
刚开始从官方下载了 PVE 最新版本6.2 安装还是很容易的,而且可以安装到usb2.0的U盘里,速度比tf卡快了很多。按网上普遍的方法直通的时候遇到了问题,直通sata和直通显卡后没办法启动会提示,网上说是HP的RMRR检查没办法禁用导致的,只能通过修改内核。
Device is ineligible for IOMMU domain attach due to platform RMRR requirement. Contact your platform
按照 https://forum.proxmox.com/threads/compile-proxmox-ve-with-patched-intel-iommu-driver-to-remove-rmrr-check.36374/ 的方法重新编译了最新版的内核5.4.41-1,更新上去之后还是无法启动提示错误
kvm: -device vfio-pci,host=0000:00:1f.0,id=hostpci0.0,bus=pci.0,addr=0x10.0,multifunction=on: VFIO_MAP_DMA failed: Invalid argument
然后继续搜索相关错误,发现都没有解决方案。又想起 国内一网友 手残的拾君 ( https://www.bilibili.com/read/cv3899236 )既然能在 HPE SL250s Gen8 上成功,就试试看修改编译和他一样的内核看看,一试还真就成功了。
具体步骤整理如下:
一、修改编译内核
参考 https://blog.csdn.net/WeDone/article/details/104337318 搭建编译环境
更换 Debian 软件包源为 163,编辑 /etc/apt/sources.list 替换为:
deb http://mirrors.163.com/debian/ buster-updates main
执行
sudo apt-get update && apt-get install -y gnupg2 wget加入 Proxmox 软件包源:
wget -qO - http://download.proxmox.com/debian/proxmox-ve-release-6.x.gpg | sudo apt-key add
echo "deb http://download.proxmox.com/debian/pve buster pve-no-subscription " | sudo tee /etc/apt/sources.list.d/buster-pvetest.list
sudo apt-get update安装编译环境:
sudo apt-get -y install build-essential asciidoc binutils bzip2 gawk gettext git libncurses5-dev libz-dev patch unzip zlib1g-dev lib32gcc1 libc6-dev-i386 subversion flex uglifyjs git-core gcc-multilib p7zip p7zip-full msmtp libssl-dev texinfo libglib2.0-dev xmlto qemu-utils upx libelf-dev autoconf automake libtool autopoint device-tree-compiler screen
sudo apt install python3-dev python3-sphinx lintian bc bison libdw-dev libiberty-dev libnuma-dev libslang2-dev lz4 rsync libpve-common-perl dh-make 根据:https://forum.proxmox.com/threads/compile-proxmox-ve-with-patched-intel-iommu-driver-to-remove-rmrr-check.36374/ 补齐部分包
apt-get install git nano screen patch fakeroot build-essential devscripts libncurses5 libncurses5-dev libssl-dev bc flex bison libelf-dev libaudit-dev libgtk2.0-dev libperl-dev asciidoc xmlto gnupg gnupg2 rsync lintian debhelper libdw-dev libnuma-dev libslang2-dev sphinx-common asciidoc-base automake cpio dh-python file gcc kmod libiberty-dev libpve-common-perl libtool perl-modules python-minimal sed tar zlib1g-dev lz4然后按 手残的拾君 ( https://www.bilibili.com/read/cv3899236 ) 的方法获取到指定的版本并进行修改产生一个diff的path文件
获取指定的版本(使用5.0.21-2 9a85bc6293ad2efb2930dde2b7123b1e008af11a 还是有些问题,不知道是我设置问题还是比的问题,系统选Windows后Bios选UEFI,开机会超时。 然后又去看看新的版本这里经过测试发现6.1的版本5.3.18-2-pve 9100f5656d3e94df55b53f6a2e33a6fc8f0fc3f2 的内核也可以使用)
git clone git://git.proxmox.com/git/pve-kernel.git
cd ./pve-kernel/
git reset --hard 9100f5656d3e94df55b53f6a2e33a6fc8f0fc3f2修改的方法见 手残的拾君 ( https://www.bilibili.com/read/cv3899236 ) 或者 https://forum.proxmox.com/threads/compile-proxmox-ve-with-patched-intel-iommu-driver-to-remove-rmrr-check.36374/
编译
make V=s二、安装核心,卸载自带的核心
上传到pve,然后安装核心
dpkg -i *.deb 卸载核心:
apt-get remove 5.4.34-1-pve -y直接卸载会提示错误,我们按给的提示操作即可。
touch '/please-remove-proxmox-ve'
apt purge proxmox-ve -y
apt-get remove 5.4.34-1-pve -y 接下来开启直通支持编辑 /etc/default/grub
找到GRUB_CMDLINE_LINUX_DEFAULT =”quiet” 改成
GRUB_CMDLINE_LINUX_DEFAULT =”quiet intel_iommu=on video=efifb:off”
更新引导
update-grub编辑/etc/modules 在最下面几行添加
vfio
一个一行,写入后保存退出,然后把显卡加入黑名单,并更新。
三、然后按照 https://blog.51cto.com/12242014/2382885 的步骤直通显卡
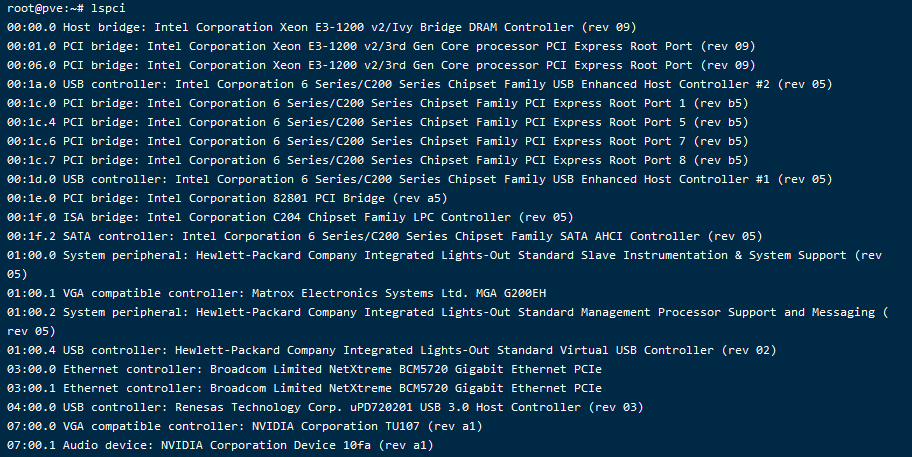
运行lspci 找到显卡的编号,我这里是07
lspci执行 lspci -n -s 07:00 获取 07的两组id
lspci -n -s 00把获取到的两个id写入/etc/modprobe.d/vfio.conf 禁用显卡并打开不安全的中断
echo "options vfio-pci ids=10de:1f82,10de:10fa" >> /etc/modprobe.d/vfio.conf
echo "options vfio_iommu_type1 allow_unsafe_interrupts=1" >> /etc/modprobe.d/vfio.conf把显卡加入黑名单
echo "blacklist nvidiafb" >> /etc/modprobe.d/pve-blacklist.conf
echo "blacklist nouveau" >> /etc/modprobe.d/pve-blacklist.conf
echo "blacklist nvidia" >> /etc/modprobe.d/pve-blacklist.conf
echo "blacklist radeon" >> /etc/modprobe.d/pve-blacklist.conf
echo "blacklist amdgpu" >> /etc/modprobe.d/pve-blacklist.conf运行以下命令加入必要的配置
echo 1 > /sys/module/kvm/parameters/ignore_msrs
echo "options kvm ignore_msrs=1">>/etc/modprobe.d/kvm.conf更新并重启
update-initramfs -k all -u && reboot添加虚拟机,BIOS选择 UEFI,机器类型选q35,添加显卡的时候要勾选 主GPU 及 PCI-Express
刚开始的时候遇到了以下一些问题
1.usb连接的声卡(Monitor 03 US Dragon),声卡不能移除,移除会导致虚拟机死机。之前连在DELL U2720QM上,显示器一关闭usb会自动断开就会死机,试了半天才找到是声卡。没办法只能移移至Gen8后面USB2.0接口长时间连接。
2.usb连接的罗技优联,移除后不能再恢复,只能通过移至Gen8 后面的usb2.0接口长时间连接。
3.能连的usb口最多5个,还不能直通usb controller。usb 3.0的Controller 连着数据U盘,内置的usb2.0连接着系统U盘这个和后面的2.0接口是同一个Controller.
4.最头疼的是 显卡虽然能用,但是性能好像大打折扣,鲁大师跑分5000多。
5.群辉怎么弄都不休眠,后来无意中发现Video Station一直在索引,影视信息一直没出来,查资料发现检索影视信息的网站被墙了。
后来修改了方案,系统安装在tf卡上(安装的时候swap分区设置成0,后续自己在usb3.0的ssd上创建一个swap文件挂載),直接通过pci直通后面的usb2.0 接口(直通的是#2控制器)给Win10虚拟机,解决了1,2问题。因为有usb2.0可以插分线器,基本也解决了问题3接口不够用的问题。
更换了内核 5.3.18-2-pve 解决了问题4,现在鲁大师跑分恢复到10万分,还是不及用Esxi 时候的11万分。
目前配置 :
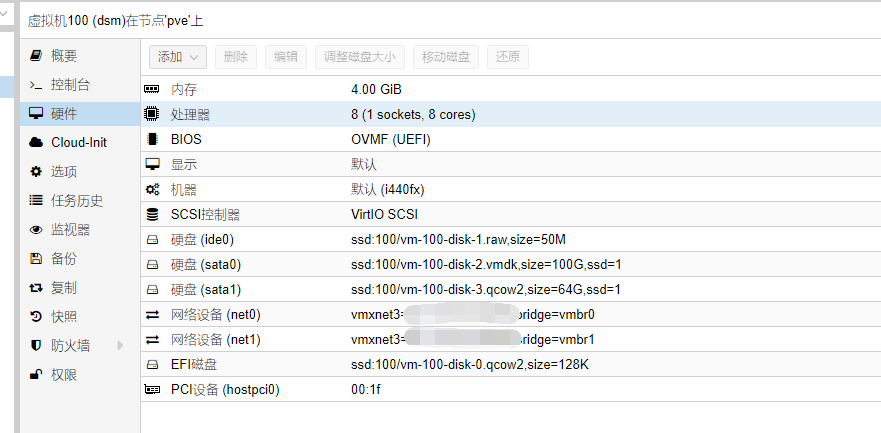
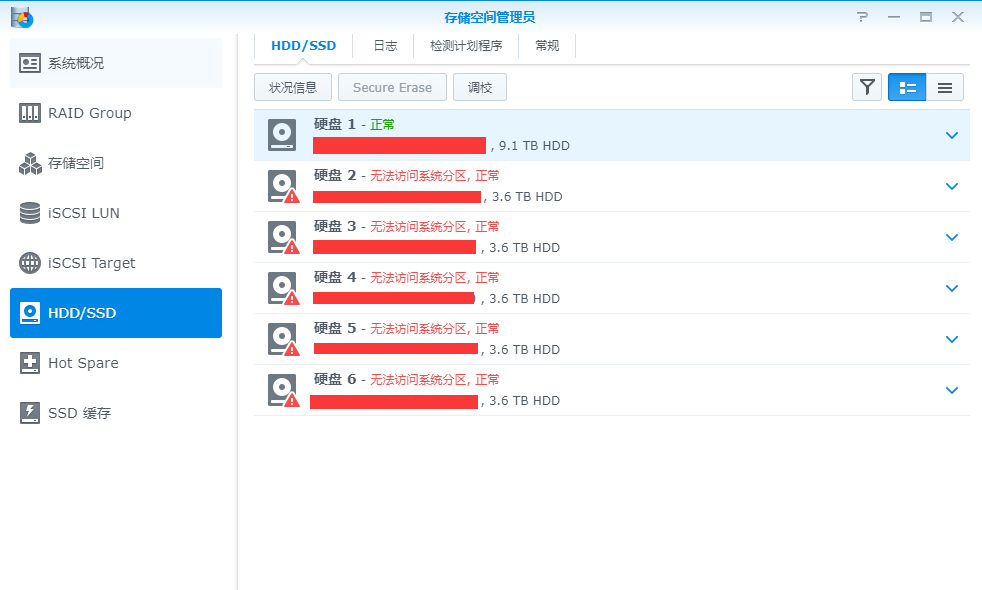
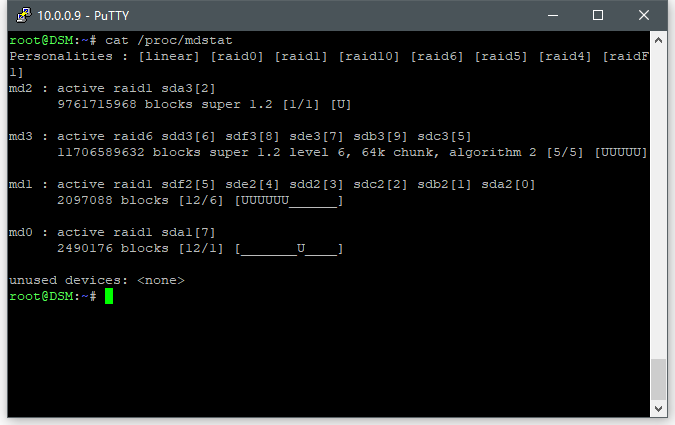
DSM:1.5G内存,直通了 SATA控制器(5块4T硬盘)+原来的ESXI中100G 放在u盘中的系统盘。
Win10:12G内存,直通usb 2.0 #2控制器+显卡
存在的问题:通过usb 直通 u盘 会导致虚拟机系统识别不了,整体性能鲁大师跑分在cpu 显卡 都低于Esxi 10%左右。
我这边用到的系统安装包以及编译好的内核
https://pan.baidu.com/s/1kubhPLL0c3rrnj-ovbe0KQ
提取码:hkvc